
자바 컬렉션
데이터를 저장하는 자료 구조와 데이터를 처리하는 알고리즘을 구조화하여 클래스로 구현해 놓을 것

컬렉션 프레임워크의 장점
- 인터페이스와 다형성을 이용한 객체지향적 설계를 통해 표준화되어 있기 때문에, 사용법을 익히기도 편하고 재사용성이 높다
- 데이터 구조 및 알고리즘의 고성능 구현을 제공하여 프로그램의 성능과 품질을 향상 시킨다
- 관련 없는 API간의 상호 운용성을 제공한다.
- 상위 인터페이스 타입으로 업캐스팅하여 사용
- 이미 구현되어 있는 API를 사용하기에, 새로운 API를 익히고 설계하는 시간이 줄어든다
- 소프트웨어 재사용을 촉진하다. 만일 자바에서 지원하지 않는 새로운 자료구조가 필요하다면, 컬렉션들을 재활용하고 조합하여 새로운 알고리즘을 만들어낼 수 있다
List 분석하기
자바9 이후에서 리스트 선언
List<String> words = List.of("Apple", "Bat", "Cat");- 여기서 of는 List 인터페이스 안에 존재하는 정적 메소드입니다.
- 만약 of 함수를 사용한다면 크기는 고정되어 어떤 데이터 타입에서도 크기를 바꿀 수 없습니다
- 그리고 이것을 불변성 이라고 부릅니다
불변성
List<String> words = List.of("Apple", "Bat", "Cat");
words.add("Dog"); //error
- of 함수를 사용해 만든 것들은 불변성을 가지기에 에러가 납니다
가변
List<String> words = List.of("Apple", "Bat", "Cat");
List<String> wordsArrayList = new ArrayList<String>(words);
List<String> wordsLinkedList = new LinkedList<String>(words);
List<String> wordsVector = new Vector<String>(words);
- 이러한 객체들은 모두 추가하는게 허용됩니다
public static void main(String[] args) {
//ArrayList 추가할 때
wordsArrayList.add("Dog");
System.out.println(wordsArrayList);
//LinkedList 추가할 때
wordsLinkedList.add("Dog");
System.out.println(wordsLinkedList);
//Vector 추가할 때
wordsVector.add("Dog");
System.out.println(wordsVector);
}
Vector, Stack, Hashtable, Properties 와 같은 클래스들은 컬렉션 프레임워크가 만들어지기 이전부터 존재하던 것이기 때문에 컬렉션 프레임워크의 명명법을 따르지 않는다. 또한 Vector 나 Hashtable 과 같은 기존의 컬렉션 클래스들은 호환을 위해 남겨진 것이므로 가급적 사용하지 않는 것이 좋다.
출처: [<https://inpa.tistory.com/entry/JCF-🧱-Collections-Framework-종류-총정리>](<https://inpa.tistory.com/entry/JCF-%F0%9F%A7%B1-Collections-Framework-%EC%A2%85%EB%A5%98-%EC%B4%9D%EC%A0%95%EB%A6%AC>) [Inpa Dev 👨💻:티스토리]
배열 메소드
words.size();
- 배열은 length 필드를 사용했지만 컬렉션은size() 메서드를 사용합니다.
- 컬렉션은 인터페이스 기반 구조이기 때문에 메서드 형태로 크기를 제공합니다
배열이 비어있는지 확인하기특정 요소 가져오기
words.get();
배열이 포함하고 있나?
words.contains("Dog");
가변 리스트 종류별 맞게 쓰는 시기
- 배열의 경우 ArrayList와 Vector에서 값을 불러올 때 빠르게 불러올 수 있습니다
- 하지만 값을 삽입하거나 제거하는 것은 매우 시간이 걸립니다
- 그 이유는 아래 이미지에 있습니다.
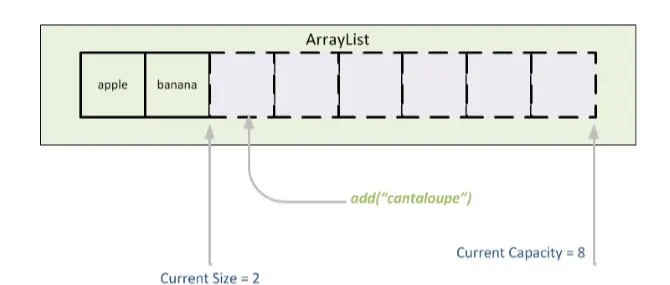
어떤 요소를 지우거나 삽입하고 싶다면 어떤 걸 먼저 찾고 모든 요소들의 위치를 변경시켜줘야 하기 때문입니다
LinkedList

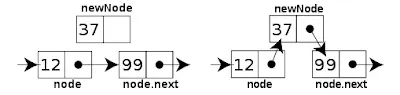
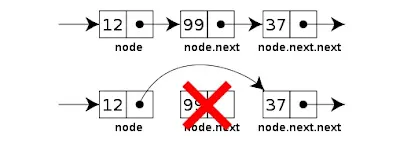
- LinkedList의 경우 전방과 후방을 연결하는 요소들로 양면 연결되어 있습니다
- 따라서 한 요소에서 다른 요소로의 참조가 들어 있으므로 요소들 접근하는 것은 매우 느립니다
- 하지만 만약 어떤 걸 삽입 또는 삭제한다고 했을 때 Array 보다는 쉽습니다
Vector
Vector는 잘 쓰이지 않는데 그 이유는 이 글을 참고해주세요.
- Vector는 많은 메소드들이 동기화되어 있습니다
- 한 클래스 안에 25개의 동기화된 메소드들이 있다고 할 때, 이 동기화된 메소드들 안에서는 한 순간에 오직 하나의 스레드만 코드를 실행시킬 수 있습니다
- 프로그램은 스레드 하나가 사용하든 15개의 스레드를 사용하든 행동방식이 바뀌면 안되니까 synchronized 가 그 역할을 하는 것입니다
메소드
더하기, 빼기, 원소 변경을 위한 메소드
- 리스트는 중복을 허용합니다
wordsArrayList.add(2, "Ball");- 인덱스를 사용해 원하는 위치에 추가가 가능합니다
- 리스트 끼리 합치기
List<String> newList = List.of("Yak", "Zebra");
wordsArrayList.addAll(newList);
wordsArrayList.addAll(2, newList); //인덱스 위치 선정도 가능
- 값 변경하기
wordsArrayList.set(6, "Fish");
- 값 삭제
wordsArrayList.remove(2); //인덱스 제거
wordsArrayList.remove("Dog"); //선택한 값 제거
- 여기에서는 우리에게 선택한 요소를 되돌려주고, ArrayList에서 그 요소를 제거하는 것
ArrayList - 원소들의 반복
public class studyCollections {
static List<String> words = List.of("Apple", "Bat", "Cat");
public static void main(String[] args) {
for (int i = 0; i < words.size(); i++){
System.out.println(i);
}
for (String word : words){
System.out.println(word);
}
}
}
- 기존에는 이런 방식의 반목문을 사용했었습니다 하지만 리스트에서는 반복문을 사용할 수 있는게 하나 더 있습니다
Iterator wordsIterator = words.iterator();
- Iterator 인터페이스를 사용하면 조금 더 간편하게 반복문을 돌릴 수 있게됩니다
- 접근법에서는 while루프를 사용하면 됩니다
import java.util.Iterator;
import java.util.List;
public class studyCollections {
static List<String> words = List.of("Apple", "Bat", "Cat");
public static void main(String[] args) {
Iterator wordsIterator = words.iterator();
while (wordsIterator.hasNext()) {
System.out.println(wordsIterator.next());
}
}
}
- 반복할 요소가 존재하고 wordsIterator가 next를 가지는 한 계속 반복하게 된다
- Vector 와 LinkedList에서도 가능
반복문이 여러 개 인 이유
- 반복문이 3가지가 존재하는 이유는 특정 작업 동안에는 특정 루프를 사용해야 하기 때문입니다
- 만약 at 로 끝나는 원소만 출력하고 싶다면
import java.util.ArrayList;
import java.util.List;
public class studyCollections {
static List<String> words = List.of("Apple", "Bat", "Cat");
static List<String> wordsAl = new ArrayList<>(words);
public static void main(String[] args) {
for(String word: words){
if(word.endsWith("at")){
System.out.println(word);
}
}
}
}- 하지만 만약에 at로 끝나는 단어를 지우려고 하면
import java.util.ArrayList;
import java.util.List;
public class studyCollections {
static List<String> words = List.of("Apple", "Bat", "Cat");
static List<String> wordsAl = new ArrayList<>(words);
public static void main(String[] args) {
for(String word: wordsAl){
if(word.endsWith("at")){
wordsAl.remove(word);
}
}
System.out.println(wordsAl);
}
}
//결과 : [Apple, Cat]
- At로 끝나는 모든 것을 지우려고 했지만 Cat은 삭제되지 않았습니다
- 그 이유는 , 개선된 for 루프를 사용할 때 루프의 중간에서 변경점을 만드는 것은 추천하지 않는 방식 입니다.
- 왜냐하면 단어를 제거함으로써 반복이 어떻게 진행되느냐가 바뀔 수 있기 때문입니다
- 이런 상황에서는 iterator 인터페이스를 가지고 하는 것이 추천된다
- 그 이유는 , 개선된 for 루프를 사용할 때 루프의 중간에서 변경점을 만드는 것은 추천하지 않는 방식 입니다.
- 그래서 만약 특정 단어를 리스트에서 제거하고 싶다면, 반복자가 가장 좋을 것이다
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class studyCollections {
static List<String> words = List.of("Apple", "Bat", "Cat");
static List<String> wordsAl = new ArrayList<>(words);
static Iterator<String> iterator = wordsAl.iterator();
public static void main(String[] args) {
while (iterator.hasNext()) {
if (iterator.next().endsWith("at")) {
iterator.remove();
}
}
System.out.println(wordsAl);
}
}
//결과: [Apple]
그냥 루프만 한다고하면 개선된 for 문이 최고이지만 제거한다고 할 때는 iterator 인터페이스가 제일 좋다
리스트 타입 안정성
import java.util.List;
public class studyCollections {
static List value = List.of("A", 'A', 1, 1.0);
public static void main(String[] args) {
System.out.println(value.get(2));
System.out.println(value.get(2) instanceof Integer);
}
}
// 1
// true
- 이 경우 리스트 타입이 뒤죽박죽 섞여있습니다
- value.get(2)에서 생성된 것은 정수가 아닌데 True가 나온 이유는 리스트 안에는 기초 요소들을 보관할 수 없기 때문입니다
- true 가 나온 이유는 오토복싱 때문
- 리스트를 만드려 할 때 일어나는 일은 이것들이 다 오토복싱되어 래퍼 클래스가 생성되는 것입니다
- value.get(2)의 경우 오토복싱의 래퍼 클래스가 정수
- 다른 요소들 모두 다 오토복싱되어 자기만의 래퍼 클래스를 갖게 됨
- 오토복싱을 허용하지 않고 리스트에서 특정한 종류의 값만 갖게 하고 싶다면 일반화가 사용됩니다
일반화
static List<String> value = List.of("A","Banana");- 위의 코드는 리스트에 스트링만 저장되게 설정했습니다
- 스트링에 정수나 더블을 넣으면 에러가 나게 됩니다
import java.util.ArrayList;
import java.util.List;
public class studyCollections {
static List<Integer> numbers = List.of(101, 102, 103, 104, 105);
static List<Integer> numberAl = new ArrayList<>(numbers);
public static void main(String[] args) {
System.out.println(numberAl.indexOf(101)); // 존재하지 않으니 0을 반환
System.out.println(numberAl.remove(101));
}
}
- 이렇게 하면 IndexOutOfBoundsException 에러가 나게 됩니다
- 그 이유는 indexOf() 메소드에서는 오버로드된 메소드가 indexOf()를 위해선 없다는 것
- 객체를 받아들이는 단 한가지 메소드가 있을 뿐
- 무엇이 일어나고 있냐면, 이 101은 정수로 오토복싱되었고 나는 정수를 검색
- 하지만 우리가 remove() 메소드를 보게 되면 두 가지가 있는 데 하나는 객체를 받아들이고, 다른 것은 인덱스를 받아들임
- 그래서 101이라 했을 때 어떤 일이 벌어지냐면 이 메소드를 사용하고 101을 정수로 오토복싱하는 대신에 무엇을 하냐면, 인덱스를 사용하는 remove 메소드로 변경시켜버린 것
배열 정렬 시키기
import java.util.ArrayList;
import java.util.List;
public class studyCollections {
static List<Integer> numbers = List.of(123, 12, 3, 45);
static List<Integer> numbersAl = new ArrayList<>(numbers);
public static void main(String[] args) {
numbersAl.sort();
}
}
java: method sort in interface java.util.List<E> cannot be applied to given types;
required: java.util.Comparator<? super java.lang.Integer>
found: no arguments
reason: actual and formal argument lists differ in length
- 기존 배열과는 다르게 비교자가 필요하다고 에러가 뜹니다
- 기본적으로, 리스트 인터페이스 안의 정렬 메소드를 사용하고 싶다면 비교자를 사용해야 합니다
- 저희는 이걸 쉽게 하는 Collections.sort 메소드를 사용할 것 입니다 -
Collections.sort
Collections.sort(numbersAl);
- sort는 Collections안에 존재하는 정적 메소드입니다
- 여기서 어떤 값이 큰 값인지 정해 줘야 합니다
- 그 정렬은 Comparable 인터페이스를 사용
package collection;
public class Student implements Comparable<Student> {
private int id;
private String name;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Student(int id, String name) {
this.id = id;
this.name = name;
}
public String toString() {
return id + " " + name;
}
@Override
public int compareTo(Student that) {
return Integer.compare(this.id, that.id);
}
}
//여기서 this는 현재 객체를 가르키며 that는 외부에서 갖고온 객체를 의미한다
package collection;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class StudentCollectionRunner {
static List<Student> students = List.of(new Student(1, "Ranga"),
new Student(100, "Adam"),
new Student(2, "Eve")
);
static List<Student> studentsAl = new ArrayList<>(students);
public static void main(String[] args) {
System.out.println(students);
Collections.sort(studentsAl);
System.out.println(studentsAl);
}
}
// [1 Ranga, 100 Adam, 2 Eve]
// [1 Ranga, 2 Eve, 100 Adam]
- 이렇게 간단하게 정렬이 되는데 만약 뒤집고 싶다면 this와 that 부분만 바꿔주면 됩니다
@Override
public int compareTo(Student that) {
return Integer.compare(that.id, this.id);
}
// 결과값
// [1 Ranga, 100 Adam, 2 Eve]
// [100 Adam, 2 Eve, 1 Ranga]
정렬 - C구현을 통해 유연성을 제공
만약 상황에 따라 다르게 구현하고 싶다면 ?
⇒ 비교자를 통해 구현
package collection;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
class AscendingStudentComparator implements Comparator<Student> {
@Override
public int compare(Student student1, Student student2) {
return Integer.compare(student1.getId(), student2.getId());
}
}
public class StudentCollectionRunner {
static List<Student> students = List.of(new Student(1, "Ranga"),
new Student(100, "Adam"),
new Student(2, "Eve")
);
static List<Student> studentsAl = new ArrayList<>(students);
public static void main(String[] args) {
System.out.println(students);
Collections.sort(studentsAl);
System.out.println("Desc" + studentsAl);
Collections.sort(studentsAl, new AscendingStudentComparator());
System.out.println("AscendingStudentComparator " + studentsAl);
}
}
/*
출력결과
[1 Ranga, 100 Adam, 2 Eve]
ASC[100 Adam, 2 Eve, 1 Ranga]
DescendingStudentComparator [1 Ranga, 2 Eve, 100 Adam]
*/
- 기본형을 이용할 때 아무 인수를 넣지 않았다면 Student 클래스 안에 있는 논리를 쓸 것이고 이렇게 오름차순과 내림차순이 출력 됩니다
- 사실 Comparator 인터페이스를 여러 번 구현할 수 있습니다
- 즉, 10가지의 다른 구현을 생성하고 10가지 다른 알고리즘을 통해 학생들을 분류할 수 있게 되는 것
- 이름을 기준으로 정렬, id를 기준으로 정렬 혹은 이름과 id의 결합으로 정렬이 가능합니다
- 어떠한 결합으로 정렬할지 스스로 정할 수 있고
- 이름을 기준으로 정렬, id를 기준으로 정렬 혹은 이름과 id의 결합으로 정렬이 가능합니다
리스트 요약
- 컬렉션 인터페이스를 연장한다
- 즉, 이것은 컬렉션 인터페이스에 있는 모든 것을 구현하고 거기에 더해서, 객체의 위치에 상관하는 메서드를 제공한다
- 그래서, 리스트의 끝이나 중간, 어디든지 요소를 삽입할 수 있다
📚 References
- Inpa Dev 👨💻, JAVA ☕ Wrapper Class - Boxing & UnBoxing
https://inpa.tistory.com/entry/JAVA-%E2%98%95-wrapper-class-Boxing-UnBoxing - TechVidvan, Java Collection Framework Tutorial
https://techvidvan.com/tutorials/java-collection-framework/ - Udemy, Best Java Programming Course
https://www.udemy.com/course/best-java-programming/
📌 함께 보면 좋은 글
- [TIL]HashSet vs TreeSet vs LinkedHashSet 차이점과 PriorityQueue 이해
- [TIL] - Java Map 구조 이해하기 — HashMap, LinkedHashMap, TreeMap 언제 사용할까?
Java Collection 팁들
- 중복된 요소들의 리스트를 저장할 수 있는 List
- 중복을 허용하지 않는 Set
- 순서가 정해지고 모든 요소가 한번만 처리되는 Queue
- 키-값 쌍을 저장하는데 쓰이는 Map
- Hash
- Collection의 이름에서 Hash를 본다면 순서도 없고 정렬도 되어 있지 않다는 걸 기억!
- 즉, 기본적으로 해시테이블 기반 Collection은 언제나 순서도 정렬도 없다
- 삽입 순서, 정렬 순서 xxx
- Linked
- 요소들이 서로 연결되어 있다는 것
- 전 요소들과 후 요소들이 연결되어 있음
- 순서는 확실히 유지됨
- 데이터 정렬 방식을 저장하지 않지만 삽입 순서대로 데이터를 저장
- 요소들이 서로 연결되어 있다는 것
- Tree
- 구조에 정렬된 상태로 저장
- 즉, 언제든지 Tree라는 키워드가 보이면 데이터가 정렬된 순서로 저장
- Tree는 기본적으로 데이터가 저장되어 있기 때문에 NavigableSet이나 NavigableMap 구현이 있을 것이다
- 즉, TreeSet은 NavigableSet을 구현하고 TreeMap은 NavigableMap을 구현하는 것
- 트리셋과 트리맵은 하위 셋을 Collection의 종류에 따라 키나 값을 이용해 하위 Set을 만들 수 있는 추가적인 작업들도 있다
'Programming Language > Java' 카테고리의 다른 글
| [TIL] - Java Map 구조 이해하기 — HashMap, LinkedHashMap, TreeMap 언제 사용할까? (0) | 2026.02.13 |
|---|---|
| [TIL]HashSet vs TreeSet vs LinkedHashSet 차이점과 PriorityQueue 이해 (0) | 2026.02.13 |
| [TIL] 인터페이스 (0) | 2026.02.06 |
| [TIL] 추상 클래스란? 개념, 사용 이유, 예제로 이해하기 (0) | 2026.02.05 |
| [TIL] 자바 객체 설계부터 상속까지 (+ toString이 자동 호출되는 이유) (0) | 2026.02.03 |